
Data Strategy
How to Assess Data Systems for AI Readiness
Jan 15, 2026
AI readiness starts with ensuring your data systems are prepared to support AI initiatives effectively. Without proper data quality, governance, and scalability, most AI projects fail. Here’s what you need to know:
80% of AI projects fail to meet goals due to poor data preparation.
67% of organizations cite data quality issues as their biggest obstacle.
AI-ready data includes anomalies and outliers, unlike traditional data management.
To assess your data systems for AI readiness, follow these five steps:
Document All Data Sources: Identify and map data sources, flows, and silos. Build a data catalog to improve accessibility and assign clear ownership.
Measure Data Quality: Evaluate metrics like accuracy, completeness, and timeliness. Set benchmarks and address gaps using automated tools.
Review Governance and Compliance: Ensure policies protect sensitive data, meet regulations, and enable secure access for AI systems.
Test Data Access and Scalability: Validate real-time data access, test system performance under load, and ensure infrastructure can grow with future demands.
Score Maturity and Plan Improvements: Rate your organization on a 1-5 scale for data quality, governance, and scalability. Develop a phased improvement plan.
Organizations that focus on these areas can achieve faster results and higher productivity while avoiding common AI pitfalls. Start by evaluating your current data landscape and setting clear priorities for improvement.
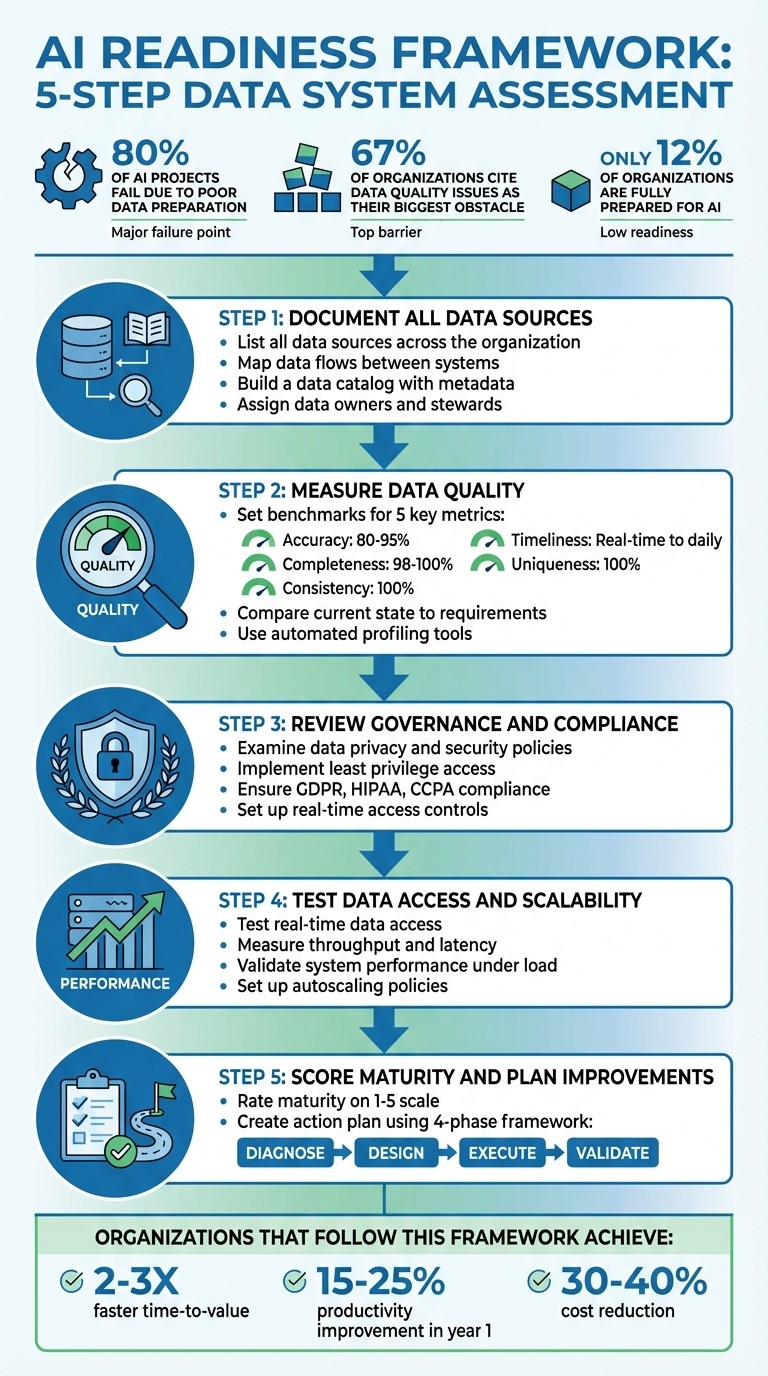
5-Step AI Data Readiness Assessment Framework
Data readiness: The backbone of AI success
Step 1: Document All Data Sources
Before diving into AI readiness, you need a clear understanding of your data landscape. Start by taking a thorough inventory of all your data sources across the organisation. This means identifying everything: structured databases, CRM systems, spreadsheets, unstructured files like emails, social media content, and even multimedia.
Map out how data flows between systems and departments. This process can uncover hidden silos, inefficiencies, and overlooked data that might be crucial for AI initiatives. For instance, your sales team might store customer insights in their own spreadsheets, never integrating them into the central database. Or your operations team might rely on isolated tools to track performance metrics. Documenting these details lays the groundwork for evaluating data quality, governance, and scalability in the steps that follow.
List All Data Sources
Start by identifying every location where your organisation stores data. This includes cloud platforms, on-premises databases, third-party APIs, and even departmental spreadsheets. Engage with data engineers, analysts, and compliance teams to uncover missing datasets, undocumented processes, or data transformations that aren't officially tracked. These conversations often reveal critical data sources that are essential for day-to-day operations but might not appear in formal records.
Assign data owners and stewards to oversee each stage of the data pipeline - from ingestion to processing and sharing. Clear ownership ensures accountability and helps maintain data quality. Without someone responsible for these processes, data can quickly degrade, leading to unreliable AI outcomes.
Build a Data Catalog
A data catalog acts as your organisation's "search engine for data", making it easier for teams to locate and understand data assets. This catalog should automate metadata collection, indexing everything from tables and columns to dashboards and jobs.
Include key metadata details in your catalog, such as the origin of the data, update frequency, who uses it, and its full transformation history. This data lineage is essential for transparency, showing how data has been processed and transformed before reaching its current state. As Idan Novogroder from lakeFS explains:
"A data catalog makes it easier to identify data, which helps employees be more productive. It provides an overview of where data originates from, how it flows through systems, and how it is altered".
Use tools like AWS Glue crawlers to automate the process of scanning repositories and collecting schema and data type information. However, building the catalog is just the start - make sure your team actively uses it. Track usage metrics to ensure the catalog is more than just a box checked off a list; it should be a resource that genuinely helps your team find and understand the data they need.
Step 2: Measure Data Quality
After documenting your data sources, the next critical step is assessing the quality of your data. Why? Because the success of your AI initiatives hinges on it. Poor-quality data can distort AI outputs, leading to unreliable insights and ineffective automation efforts.
As Gartner points out:
"High-quality data - as judged by traditional data quality standards - does not equate to AI-ready data".
The trick is to pinpoint which quality metrics are most relevant to your specific AI use case. For instance, the accuracy requirements for predictive maintenance differ from those for a generative AI chatbot. With this in mind, it’s essential to establish clear quality benchmarks for your data.
Set Data Quality Benchmarks
Focus on metrics like accuracy, completeness, consistency, timeliness, and uniqueness. Each metric plays a distinct role in ensuring your data is fit for purpose:
Accuracy: Does the data accurately reflect real-world events? Depending on your use case, aim for an accuracy rate of 80% to 95%. For instance, retail companies often target 95% accuracy in customer contact information to improve engagement.
Completeness: This is measured as (complete data elements)/(total data elements). Critical fields - like customer email addresses or product SKUs - should aim for 98% to 100% completeness. Missing these can derail AI training.
Consistency: Ensures data is standardised across systems, which is crucial for interoperability.
Timeliness: The required freshness of your data varies. Fraud detection might demand real-time updates, while trend analysis may only need daily updates.
Uniqueness: This metric identifies duplicate records using the formula: (Total records - Duplicates)/(Total records). Strive for 100% uniqueness to avoid skewed analyses.
Interestingly, AI models often benefit from datasets that include some errors and outliers. While a perfectly scrubbed dataset may look clean, it might fail to teach your AI to identify anomalies like unusual purchasing patterns or fraudulent behaviour.
Additionally, keep an eye on null counts in key columns, as these can signal data drift or system issues. Monitor the frequency of data updates to avoid "data staleness", especially in fast-paced environments like financial trading. Real-time validation during data entry can also help preserve integrity from the start.
Compare Current State to Requirements
Once benchmarks are established, compare your current data quality against these targets. Data profiling tools can help you analyse the structure, content, and relationships within your datasets, exposing issues like inaccuracies and inconsistencies. Automated validation and AI-driven observability tools are also invaluable for detecting anomalies and accuracy drift as data flows through your pipelines.
Here’s an example of how to visualise gaps between your current data quality and AI readiness:
Data Quality Dimension | Current Score | AI Readiness Target | Gap | Priority |
|---|---|---|---|---|
Accuracy | 72% | 80%-95% | -8% to -23% | High |
Completeness | 85% | 98%-100% | -13% to -15% | Critical |
Consistency | 78% | 100% | -22% | High |
Timeliness | Daily updates | Real-time | Significant | Medium |
Uniqueness | 92% | 100% | -8% | Medium |
This type of analysis highlights where your efforts should be focused. For instance, if your completeness score is 85% but you need 98% for critical fields, addressing that gap should be a top priority. Use automated data-cleaning tools to fix formatting errors, eliminate duplicates, and standardise data fields. For more complex datasets, human experts may be needed to validate edge cases that automated tools might misinterpret.
Throughout this process, tracking data lineage is vital. Understanding your data’s origin and transformation history builds trust in your AI outputs and ensures accuracy. As Alation explains:
"DQA involves various techniques and practices aimed at improving data accuracy, completeness, consistency, and reliability".
Finally, rank improvement areas by their impact on your AI use case and the resources required to address them. This prioritisation will form the backbone of your action plan in Step 5.
Step 3: Review Data Governance and Compliance
Once you've assessed data quality, it's time to focus on your data governance framework. Strong governance is the backbone of AI success - it helps prevent data breaches, ensures compliance, and minimizes security risks. Without it, AI systems can unintentionally expose sensitive data, cross regulatory boundaries, or create vulnerabilities.
Here's a striking fact: over 75% of executives believe that data silos hinder collaboration and weaken their competitive edge. These silos often exist because of weak governance, which fails to provide secure and efficient data access. The challenge lies in crafting a framework that protects sensitive information while allowing AI tools to operate effectively.
Examine Governance Policies
Start by reviewing policies related to data access, protection of sensitive information, and compliance with regulations. A solid governance framework should cover several key areas:
Data Privacy and Security: Implement measures like encryption, access controls, and safeguards to comply with laws such as GDPR, HIPAA, and CCPA.
Model Selection and Validation: Establish formal processes for onboarding models, including using sandbox environments for testing.
External Tools and Datasets: Create policies to vet third-party tools and data sources, reducing security and ethical risks.
Matt Sullivan, Director of Technical Account Management at Alation, offers this advice:
"You start off small with a small set of data and a small set of policies, and then eventually you mature out to more robust processes and tackle additional data domains".
Don't forget to address data residency and sovereignty to comply with local storage laws. It's also important to clearly disclose AI's role in systems and assign human accountability for decisions and outcomes. To enforce these policies, tools like Microsoft Purview or Azure Policy can provide real-time monitoring and immediate responses to violations, reducing human error.
With well-defined governance policies in place, the next step is to ensure real-time access controls are effective.
Check Real-Time Access Controls
Real-time access controls are critical for maintaining security without creating bottlenecks. The principle of least privilege access is key - AI systems should only access the specific data they need for their tasks, rather than having unrestricted access across the organization. This approach prevents unauthorized data crawling and ensures sensitive information, like credit card numbers or health records, remains protected.
To enhance security, ensure AI systems inherit user-specific permissions through identity tokens. This ensures that AI agents only access data that the user is authorized to view. Assign unique identities to AI agents (e.g., using Microsoft Entra) to track ownership and version history. Additionally, use Data Loss Prevention (DLP) policies and sensitivity labels to automatically limit the data that AI agents can access or include in their responses.
It's also wise to separate internal business AI systems from public-facing agents by using logical boundaries or distinct management groups. This reduces the risk of accidental data exposure. Standardize knowledge integration through official APIs and connectors to maintain control. Finally, implement centralized logging solutions like Azure Log Analytics to monitor agent activities, user interactions, and resource usage in real time. These logs are invaluable for auditing and managing AI's unpredictable behavior.
Step 4: Test Data Access and Scalability
Testing your system's ability to handle data access and scalability is a critical step in ensuring your AI applications perform as intended. It's not just about functionality - it's about making sure your infrastructure can support real-time operations and adapt to growing demands. Without this, bottlenecks can surface, derailing even the most advanced AI initiatives.
Here’s a stark reminder: 96% of organisations have encountered barriers limiting their AI adoption. In many cases, these challenges arise from infrastructure that simply can't keep up. By rigorously testing your setup under realistic conditions, you can identify and address these issues before they result in costly production failures.
Test Real-Time Access
For AI to work effectively, it needs immediate, uninterrupted access to data. This means testing more than just the accuracy of your models. Focus on functional and integration tests to ensure your systems can handle requests smoothly and structure responses correctly. For generative AI workloads, pay attention to token-level throughput rather than just counting API calls.
Performance testing is key. Measure throughput, latency, and resource usage under simulated loads. Push your system by introducing failures to see how it reacts. For example, test how well it handles HTTP 429 throttling errors, backend timeouts, and service outages. Validate that retry logic, backoff mechanisms, and circuit breakers are functioning as intended.
If your system relies on grounding data, examine the entire workflow - from sourcing documents to preprocessing and orchestration. Make sure the index delivers accurate, real-time data during interactions. For AI agents that depend on external tools, use mock dependencies and predefined scenarios to verify connections and responses.
Once you've confirmed real-time access, shift focus to scalability - your infrastructure's ability to grow alongside your data demands.
Measure Scalability
Testing current performance is just the beginning. The real challenge is determining whether your infrastructure can handle the data volumes of tomorrow. Load and stress tests are essential here. Push your systems beyond their normal operating conditions and monitor critical metrics like GPU usage, RAM allocation, and CPU cores. Keep an eye on the behaviour of your search index under various loads to identify potential bottlenecks in compute resources or storage.
Your system’s query performance should remain consistent, even during intensive tasks like background reindexing or periods of heavy concurrent usage. In scenarios where real-world data is limited - such as fraud detection - synthetic data can fill the gaps, allowing you to validate transformations and test scalability safely.
Knowing your system's limits now can guide smarter investment decisions later. Ask your engineering team the tough questions: How quickly can new data sources be ingested? Can your system handle datasets large enough to meet the model's needs? Are Change Data Capture (CDC) tools in place for continuous data loads?
Finally, set up autoscaling policies with clear thresholds. This ensures your systems can adapt to fluctuating AI workloads without requiring manual intervention. By preparing for growth now, you can ensure your infrastructure supports your AI goals rather than holding them back.
Step 5: Score Maturity and Plan Improvements
After completing your testing and quality assessments, the next step is to evaluate your maturity and create a roadmap for improvement. This process translates your findings into actionable priorities. Without a clear maturity score, it’s hard to establish benchmarks or identify where to focus investments.
Rate Maturity Levels
To assess your organisation’s standing, use a 1-5 scale across four key areas: data quality, governance, accessibility, and scalability. This straightforward scoring system provides an objective view, cutting through subjective opinions to reveal your true position.
Here’s what each level represents:
Maturity Level | Data State | Governance State | Infrastructure & Scalability |
|---|---|---|---|
1: Unprepared | Disconnected, low-quality, spreadsheet-based | No formal policies or shared definitions | Outdated, on-premises systems; no machine learning capabilities |
2: Planning | Identified but not governed; inconsistent versions | Policies exist but are weakly enforced | Planning for cloud migration; tools operate in silos |
3: Operational | Catalogued; quality scores 70–85% | Policies enforced; basic trust in metrics | Cloud adoption in progress; reliable data pipelines |
4: Advanced | Governed; quality scores above 85% | Mature oversight; metadata and lineage documented | Modern, scalable cloud systems; automated MLOps pipelines |
5: Leading | Real-time, high-quality, strategic asset | Automated compliance and ethics integrated | AI-optimized systems; continuous innovation through automation |
For optimal readiness, aim for data quality scores of 80% or higher in accuracy, completeness, and consistency. Falling below Level 3 in any category can create major obstacles for AI implementation. In fact, 60% of AI success depends on data readiness, not just infrastructure.
As Maddie Daianu, Senior Director of Data Science & Engineering at CreditKarma, explains:
"Data needs to be considered and intertwined with AI and machine learning to really unlock meaningful value... it reaches its full potential when we have high quality data".
Once you’ve determined your maturity level, the focus shifts to addressing gaps and improving readiness.
Create an Action Plan
With your maturity scores in hand, you can use Rebel Force’s 4-phase framework to systematically tackle weaknesses:
Diagnose: Start by conducting a thorough inventory of your data sources, infrastructure, and talent. Use your scores to pinpoint which pillars - Strategy, Data Foundations, Technology Infrastructure, People, Governance, or Use Cases - need immediate attention [5,31].
Design: Build a roadmap by prioritising initiatives based on their potential ROI and feasibility. Not every area needs to reach Level 5; align your goals with specific business needs. Focus on high-value, low-complexity projects to avoid getting stuck in "analysis paralysis" and ensure resources are used strategically.
Execute: Begin improvements by strengthening your data foundations. Invest in tools to achieve the critical 80%+ data accuracy benchmark. Upskill your team or bring in experts as needed. Studies show readiness assessments can cut costs by 30–40%.
Validate: Measure success through clear financial metrics (e.g., cost savings, revenue growth) and operational KPIs (e.g., efficiency gains, error reduction). Organisations with strong AI readiness often see productivity improvements of 15–25% within the first year and achieve results 2–3 times faster.
This phased approach ensures a strong foundation before diving into AI projects, reducing the risk of failure. With 80% of AI projects failing due to inadequate preparation, scoring maturity and planning improvements is not just helpful - it’s critical.
Conclusion
Evaluating data systems is a critical step for any successful AI initiative. The five-step process - documenting data sources, measuring quality, reviewing governance, testing access and scalability, and scoring maturity - offers a structured approach. Yet, only 12% of organizations are fully prepared to implement AI effectively.
To create AI-ready data, organisations need strong governance, modern infrastructure, and scalable systems. Those that invest in these areas can achieve results like 2–3 times faster time-to-value and productivity boosts of 15–25% within the first year. Without these foundational elements, even the most advanced AI models may fall short of expectations.
Rebel Force's 4-phase framework - Diagnose, Design, Execute, Validate - builds on these steps, helping organisations focus on high-impact use cases and measurable returns. This approach not only aligns AI efforts with business goals but also reduces implementation costs by 30–40%, avoiding costly missteps and rework. Shifting data ownership from IT to business teams ensures that AI initiatives remain strategically driven rather than becoming isolated technical projects.
With clear benchmarks and a solid action plan, you can gain executive support, allocate resources wisely, and measure progress using concrete financial and operational metrics. Start by identifying your most valuable AI use case and aligning your data systems to support it. The organisations succeeding with AI aren’t necessarily the most technologically advanced - they’re the ones that laid a strong foundation first.
FAQs
How can I prepare my data systems for AI while ensuring quality and compliance?
Preparing your data systems for AI involves first identifying the specific AI applications you plan to implement and aligning your data requirements to match those needs. Start by ensuring your data is consistent, complete, and machine-readable. This means standardizing formats, addressing any gaps, and applying proper labels to make the data ready for both AI training and operational use.
Strong data governance is also crucial. Define clear roles for managing data pipelines, use automated testing to track accuracy, and enforce role-based access controls to maintain security and compliance. Regularly monitor key metrics like error rates and data freshness to ensure your systems stay reliable as your AI models evolve.
For a smoother transition, Rebel Force offers support in creating and executing a customised enablement plan. Their expertise can help optimise your data systems for AI integration, delivering tangible results for your business.
How can I test if my data systems are scalable for AI projects?
To ensure your data systems are ready to handle AI workloads at scale, it's essential to take a thoughtful and structured approach. Here's how you can do it:
Simulate AI scenarios: Start by estimating the data volume, model demands, and performance goals you'll encounter in production. For example, you might need to manage 1,000,000 requests daily with a response time under 10 milliseconds.
Set up a realistic testing environment: Build a test setup that closely mirrors your production system. This includes replicating storage, compute, and network configurations to ensure accuracy.
Conduct load testing: Gradually increase data traffic and request rates to replicate peak usage conditions. Keep a close eye on key metrics like CPU/GPU usage, memory consumption, storage efficiency, and network bandwidth to spot any weak points.
Refine and retest: When performance thresholds are exceeded, adjust resources accordingly - whether that means increasing compute power or expanding storage. Then, retest to confirm that your system can handle the load consistently.
Keep detailed records of your findings to shape a clear scaling strategy. If you need expert help, Rebel Force can work with you to design and implement a customised solution that aligns with your goals, ensuring your systems are optimised for AI and ready to support long-term growth.
How can I evaluate if my organization's data systems are ready for AI integration?
To determine how well your data systems are prepared for AI, you can use an AI maturity framework. This framework evaluates critical areas such as data quality, governance, accessibility, integration, and security. Each area is assigned a maturity level - ranging from initial to optimized - to calculate an overall readiness score.
By using this method, you can pinpoint weaknesses and uncover opportunities to enhance your systems. This ensures they’re capable of supporting scalable, AI-driven solutions. If you need a more customized approach, consulting with specialists in AI-ready system design and implementation can help you achieve tangible results.